Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour. It has almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour, with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world.
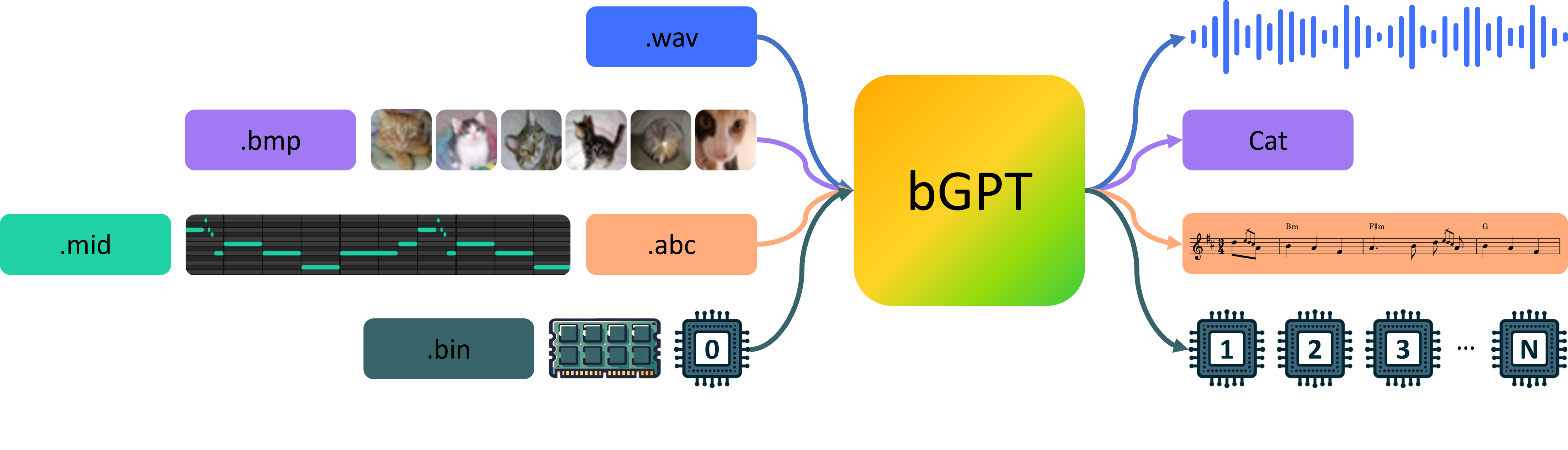
Bytes are the foundation of all digital data, devices, and software, from computer processors to operating systems in everyday electronics. Therefore, training models for next byte prediction can potentially lead to a paradigm shift in deep learning, allowing them to truly understand and simulate all activities in the digital world. This has practical benefits not only in conventional areas, but also in some underexplored areas such as boosting cybersecurity, improving computer diagnostics, optimizing data compression, and even advancing complex tasks like reverse-engineering the source code of that software from its binary representation.
In this paper, we introduce bGPT, a model designed for binary data processing and digital world modelling by next byte prediction. The digital world includes not only digital media files, traditionally the focus of deep learning models, but also extends to the intricate realm of digital systems, ranging from hardware architectures to complex algorithms. bGPT transcends traditional deep learning boundaries by directly interpreting and manipulating binary data, enabling a more intrinsic and holistic understanding of the digital world. Its advantages are two-fold: 1) Interpreting Digital System: By training on byte sequences, bGPT can learn the patterns of digital systems, enabling it to predict, simulate, and diagnose algorithm or hardware behaviour. This ability allows for the reconstruction of complex systems from binary data. 2) Unified Modelling: bGPT integrates various data types into a single framework, treating everything as a byte sequence. This simplifies modelling and allows for easy integration of various data sources.
Our experiments include two main areas: 1) well-studied tasks like generative modelling and classification on digital media data (e.g., text, audio, and images); and 2) relatively underexplored tasks intrinsic to binary-native operations, including data conversion and CPU state modelling, which represent algorithm and hardware simulation, respectively. The demo page sequentially showcases models pre-trained on IrishMAN for data conversion, CPU states for CPU state modelling, Wikipedia for text, ImageNet for images, and LibriSpeech for audio. All showcased generative samples from bGPT are produced using the same data preprocessing, model architecture, hyperparameters, and training objectives, without any modality-specific customizations.
This process involves converting data from one format to another, with symbolic music formats such as ABC notation and MIDI files serving as our main examples. For background information on ABC notation and MIDI, please refer to Appendix A in our paper. In this task, bGPT employs the generative modelling approach on concatenated byte sequences of paired ABC and MIDI files, separated by a special patch. The bGPT model learns to convert text-based ABC notation music scores into binary MIDI performance signals and, reversely, convert MIDI back into ABC notation. This necessitates the ability to simulate and reverse-engineer the conversion algorithm, which indicates an essential capability for modelling the digital world.
In our data conversion tasks with bGPT, we found that the model typically achieves highly accurate conversions between ABC notation and MIDI files, closely mirroring the ground truth. Despite occasional decoding issues with converted MIDI files, bGPT demonstrates the remarkable capability to correct source data errors or more compactly encode conversions without losing accuracy. Below, we present a set of examples that illustrate these capabilities, including bGPT-converted MIDI from ABC notation, ABC notation from MIDI, and the original MIDI and ABC notation data for reference. For ease of demonstration, we've rendered each piece of data into MP3 audio and PDF sheet music. You can download the original data pack here.
The model is fed with concatenated sequences of low-level machine instructions followed by a series of CPU register states. The objective is to accurately predict how the state updates with each instruction until the program halts. This task demonstrates the capacity of bGPT to interpret operational data and replicate digital activities within hardware.
For CPU state modelling, we introduce the CPU states dataset (with 2.1 million instances), offering a simplified representation of CPU behaviour for ease of data collection and evaluation. Each dataset instance contains a 1KB memory block with varying numbers of machine instructions, followed by a sequence of 16-byte CPU register states. These states include various instructions, totaling 21 unique types with 43 variants, such as data movement, logical operations, and arithmetic operations. Within each state, 1 byte each is allocated for the Program Counter (PC) and Accumulator (ACC), 4 bytes are allocated for the Instruction Register (IR), with an additional 10 bytes reserved for general-purpose registers. Instances are generated by executing random sequences of 1 to 256 instructions and capturing the state after each execution. Despite simplifications, this dataset effectively simulates typical CPU behaviour. See Appendix B in our paper for more details.
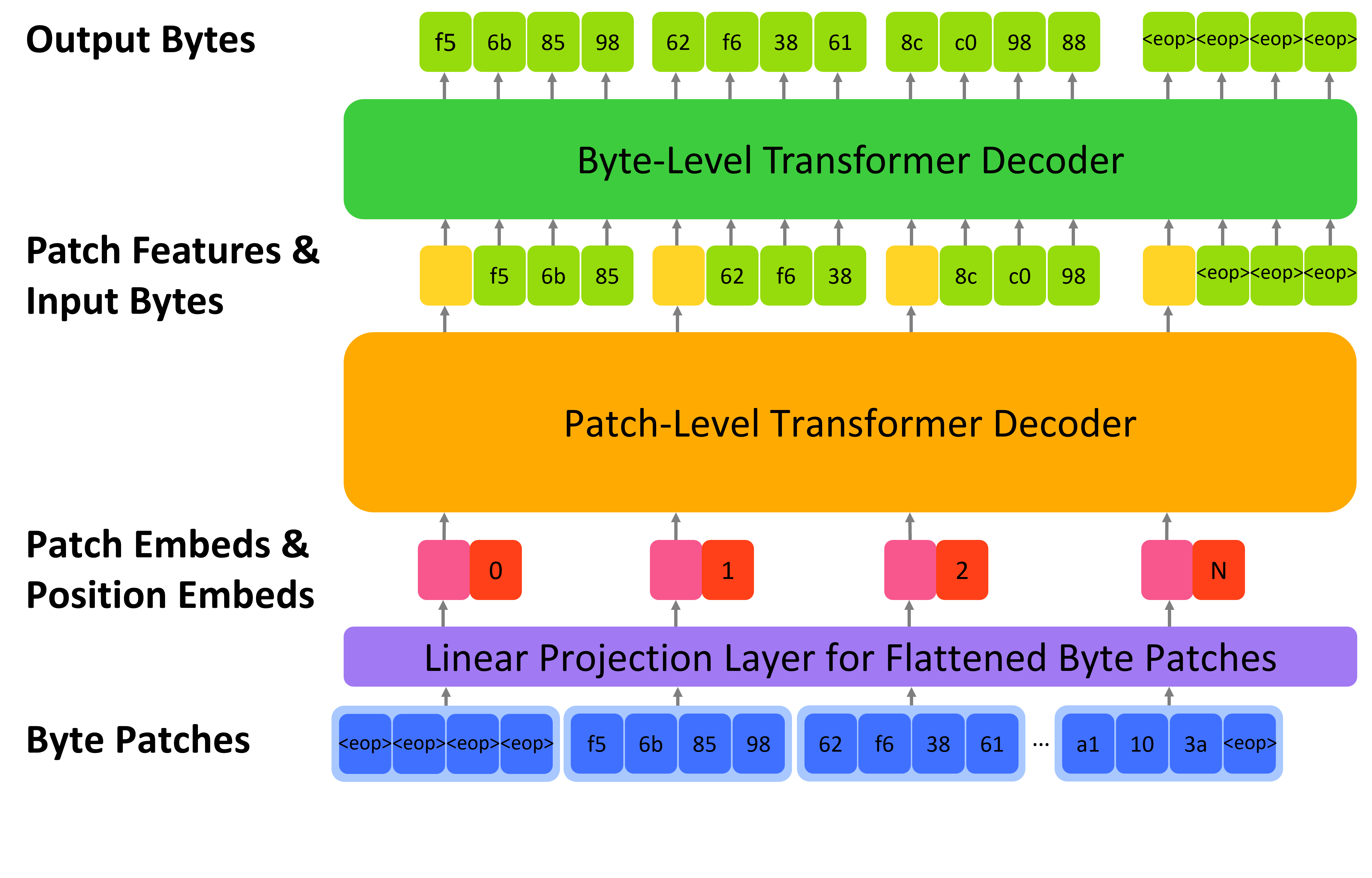
bGPT diverges from traditional subword encoding by adopting byte-level text encoding, which requires no vocabulary and thus supports any language. This method, akin to character-level encoding but potentially longer for non-European languages due to multi-byte characters, increases computational demands. To mitigate this, bGPT utilizes a hierarchical Transformer architecture capable of producing texts up to 8KB in size, significantly surpassing the typical 3KB to 4KB output of GPT-2 (where each token occupies 3-4 bytes). Pre-trained on Wikipedia, bGPT is capable of generating texts that exhibit a stylistic and thematic fidelity comparable to GPT-2. However, it may also produce logical inconsistencies or inaccuracies, limitations commonly found in models of the 110M scale, especially in extended texts. Furthermore, it occasionally struggles with non-English terms, a consequence of its primary training on English Wikipedia content. Despite these limitations, bGPT exhibits fewer degeneration cases (i.e., repetition), compared to GPT-2. Below, we present a set of examples that illustrate these capabilities, including optimal and poor examples generated by bGPT, as well as GPT2-generated and real Wikipedia articles for reference.
bGPT is capable of generating images by predicting the next byte in a sequence of bytes that represent an image. The model is pre-trained on the ImageNet dataset, and it generates images with a resolution of 32x32 pixels. Due to the sequential processing nature of byte-level encoding, bGPT struggles to capture the essential two-dimensional spatial relationships within images (Yu et al., 2023) at the current scale. This results in images with noticeable artifacts and noise, as well as a lack of coherent structure. Despite this, simply scaling the model size while retaining this sequential processing approach could still hold promise for achieving state-of-the-art results (Chen et al., 2020). Below, we present a set of examples that illustrate the capabilities and limitations of bGPT, including examples generated by bGPT, as well as real images from the ImageNet dataset for reference.


By modelling audio data as a sequence of bytes, bGPT can generate audio samples with a duration of 1 second with a sampling rate of 8000 Hz. The model is pre-trained on LibriSpeech, segmented into 1-second clips, making the 1-second duration Speech Commands v2 ideal for fine-tuning and showcasing. The generated audio samples are of varying quality, with some examples being nearly indistinguishable from real audio, while others contain noticeable artifacts and noise. Below, we present a set of examples that illustrate the capabilities and limitations of bGPT, including good and poor examples generated by bGPT, as well as real audio samples from the Speech Commands v2 dataset for reference.
The bGPT model demonstrates its strength in the versatility and adaptability of byte models, capable of processing a wide range of data types, including traditional media formats. This capability marks a significant departure from the limitations associated with conventional deep learning models, which are typically confined to specific formats and tasks. By directly operating on native binary data, bGPT facilitates the modelling of algorithm or hardware behaviours, offering a unique advantage.
Nonetheless, our experiments illuminate opportunities for improvement. In this study, we confine the modelling to short audio segments and low-resolution images, a consequence of the resource-intensive nature intrinsic to byte models. Due to limited computational resources, we only investigated data conversion between ABC notation and MIDI, without broader assessments across alternate formats. Furthermore, to simplify data collection and evaluation, our CPU state modelling experiments focused solely on simplified CPUs, omitting the use of real modern CPUs, which are considerably more complex.
Future research directions for byte models include: 1) reducing computational cost to make training byte models more feasible; 2) scaling models and dataset sizes to accommodate a broader range of native binary data, as well as handling larger digital media files such as high-resolution images and videos; and 3) improving model performance, particularly for underexplored tasks involving native binary data across diverse application domains.
@misc{wu2024language,
title={Beyond Language Models: Byte Models are Digital World Simulators},
author={Shangda Wu and Xu Tan and Zili Wang and Rui Wang and Xiaobing Li and Maosong Sun},
year={2024},
eprint={2402.19155},
archivePrefix={arXiv},
primaryClass={cs.LG}
}